
Runbook Automation in 2025: A Practical Playbook to Cut MTTR, Reduce Toil, and Ship with Confidence
When an alert fires at 2:07 a.m., the difference between a five-minute wobble and a painful outage often comes down to how quickly your team can execute the right steps, in the right order, safely. That is the promise of runbook automation: take the best version of your procedures-those tribal steps scattered across a wiki, Slack, and muscle memory-and turn them into executable, observable, and auditable workflows. Instead of pasting commands into terminals, engineers press a button (or let events trigger a workflow) and watch guardrailed actions validate assumptions, make changes, and verify outcomes.
This guide is a practical, buyer-friendly tour of runbook automation. You’ll learn what it is (and isn’t), how it improves reliability and velocity, the capabilities that matter in tools, and how to roll out a program that measurably lowers MTTR while strengthening security and compliance. We’ll also highlight one section that’s tailor-made for an infographic your stakeholders will love.
What Is Runbook Automation?
Definition and Core Concept
A runbook is a step-by-step procedure for a routine operational task. Runbook automation (RBA) converts that procedure into a workflow that can be triggered by alerts, schedules, or humans. The workflow performs pre-checks, runs actions, handles errors, and confirms the system is healthy-with evidence. Unlike a static document or a gist, automated runbooks are versioned, permissioned, and observable. They aren’t just instructions; they’re the engine that enforces those instructions consistently.
How Runbook Automation Works
RBA differs from generic scripting in a few critical ways. First is determinism: steps run in a controlled order with timeouts, retries, and rollbacks, so failure modes are designed-not discovered. Second is composability: reusable blocks (auth, notifications, validations) reduce drift and duplication. Third is governance: approvals, RBAC, and immutable logs keep risky actions within policy and make audits routine instead of stressful.
Runbooks, Playbooks, and SOPs: Clearing the Vocabulary
Teams often conflate these terms, and it creates confusion during incidents. An SOP is a policy-level narrative: scope, roles, and rules. A playbook is scenario-driven: if the database is slow, check replicas, throttle background jobs, then remediate X or Y. A runbook is the executable unit that actually does the work-drains traffic, restarts a service, rotates keys, or flips feature flags-and then verifies that change succeeded. In practice, a playbook orchestrates one or more automated runbooks, while SOPs set the constraints that runbooks must respect (for example, “production restarts require an SRE approval”).
Keeping the concepts separate helps you scale the program. You can refine strategy (playbook) without rewriting every step, and you can improve execution (runbook) while keeping policy stable. This division of responsibilities is what turns heroics into a repeatable system.
Why Runbook Automation Now? The Business Case
Modern systems are too fast and too complex to rely on memory and heroics. RBA reduces Mean Time to Repair (MTTR) by turning the first five minutes of a response from “discussion” into “execution.” It lowers error rates because parameter prompts, pre-checks, and idempotent actions prevent misfires. It increases delivery velocity by making risky operations-cutovers, rollbacks, data cleanup-repeatable and safe. And it reduces toil so senior engineers spend more time strengthening the system rather than babysitting it.
There’s also a trust dividend. Automated runbooks produce artifacts-logs, approvals, metrics screenshots-that transform post-incident reviews from finger-pointing into learning. When the organization can see what happened and why, it becomes easier to invest in resilience instead of patches.
Core Capabilities to Expect in an RBA Platform
A mature platform should meet your team where it works (alerts, chat, ITSM) and integrate cleanly with your stack. While every vendor markets similar buzzwords, a few capabilities separate slideware from systems you’ll trust in production:
Triggering & Orchestration:
Event-driven, scheduled, and human-initiated runs; branching, parallelism, and fan-in/fan-out for complex flows.
Integrations & Extensibility:
Native connectors for clouds, CI/CD, monitoring, messaging, ITSM, and security tools; the ability to run containers/scripts and call APIs with retries and timeouts.
Human-in-the-Loop Controls:
Role-based access, approval tiers by risk, safe parameter prompts with validation, and time-boxed access for emergencies.
Secrets & Security:
Per-step credentials, centralized secret stores, redaction in logs, environment scoping, and least-privilege policies.
Observability & Evidence:
Live run views, per-step timing, structured logs, artifact capture, and easy export to SIEM/APM.
Governance & Compliance:
Versioning with diffs, promotion (dev → stage → prod), change approvals, and immutable audit trails.
Usability for Both Personas:
No-code/low-code builder for operators plus CLI/SDK for engineers to test, lint, and automate promotion.
High-ROI Use Cases Across Teams
SRE / Platform Engineering
- – Drain and restart noisy services with pre/post health checks
- – Cache eviction followed by warm-up ahead of traffic spikes
- – Canary/blue-green cutovers with automated health verification and instant rollback on SLO regression
IT / Business Operations
- – Zero-touch onboarding/offboarding (accounts, groups, licenses, device setup) with evidence attached to ITSM tickets
- – Scheduled license reconciliation and data hygiene jobs with exception reporting to finance/compliance
- – Standardized laptop build/rebuild workflows tied to asset management
Security / Incident Response
- – Alert-triggered host isolation with forensic snapshotting and approvals
- – IAM key rotation with consumer validation, staged cutover, and revocation of old keys
- – Blocking IOCs across EDR, email gateway, and firewall, with stakeholder notifications
Data & Analytics
- – Unstick ETL pipelines using safe retries, backoff, and idempotent steps
- – Regenerate materialized views while honoring downstream SLAs and freshness checks
- – Rotate storage credentials across Airflow/DBT with automatic secret propagation and post-checks
Designing a Safe, Auditable Runbook
Treat each runbook like production code. Start with metadata-owner, purpose, risk classification, last change date-so anyone can evaluate scope at a glance. Add pre-checks that validate state before you touch anything: dependency health, error budgets, similar actions in the last hour, or a maintenance window. Write idempotent execution steps with guarded commands and bounded concurrency. Follow with verification that queries health endpoints and live metrics to confirm the desired state. Always include a rollback path with its own checks. Close with notifications that summarize inputs, actions, outcomes, and links to artifacts for review.
A good litmus test: if a new teammate can read the runbook and predict what it will do and how it will fail safely, you’ve designed it well.
Implementation Roadmap: From Pilot to Scale
Phase 1
Your first quarter with RBA should feel like a product launch, not a science project. Begin by identifying three to five high-frequency, low-risk tasks that cause real pain-service restarts with validation, queue flushes, user unlocks, credential rotations. Draft the “golden path,” then layer in pre-checks and post-checks. Decide triggers for each runbook (alert, webhook, schedule, or manual). Define who can run it, who must approve, and who gets notified on success/failure.
Phase 2
Before promoting to production, shadow-run the workflows during real incidents or drills. Compare automated outcomes to manual results and capture operator feedback: Were prompts clear? Were logs useful? Did timeouts feel appropriate? Iterate quickly. Instrument the program with a simple dashboard: time to first action, run success rate, average duration, and MTTR for scenarios covered by automation. Share these numbers widely; they build credibility and momentum.
Phase 3
As confidence grows, expand to deployment-adjacent tasks (pre-deploy checks, post-deploy verifications, feature flag flips) and to resilience engineering routines (backup/restore drills, failover rehearsals). At this stage, invest in reusable blocks and templates so a change in one place improves many runbooks.
Security and Compliance: Guardrails That Scale
Automation magnifies both good and bad practices. Enforce least privilege at the step level so a run that rotates a database password can’t drop tables. Maintain separation of duties: builders shouldn’t self-approve production-impacting changes. Use time-boxed approvals for risky actions and ensure secrets never touch logs. Version all runbooks, require code review for high-risk operations, and keep immutable evidence-inputs, approvals, outputs-attached to tickets. When auditors arrive, you’ll have proof, not promises.
For regulated environments, map runbooks to change records and incident timelines automatically. The ability to show “who did what, when, and why” in seconds saves weeks of compliance toil each year.
Metrics That Matter (and How to Use Them)
Start with Time to First Action. The first goal of RBA is to turn minutes of debate into seconds of action. Next, track MTTR for incident classes with automated remediation and compare it to manual classes; use the delta to prioritize your next runbooks. Monitor change failure rate for runbook-initiated actions; improving pre-checks and verification should lower it over time. Measure automation coverage-the percentage of your top incident types with at least one automated path. Finally, add a lightweight operator confidence survey after incidents to surface unclear prompts or missing context.
Interpretation matters. If Time to First Action improves but MTTR doesn’t, you likely automated starts without robust verification or rollback. If change failure rate is flat, add better idempotency, canary validation, and guarded rollbacks. Use metrics not as vanity, but as a backlog engine.
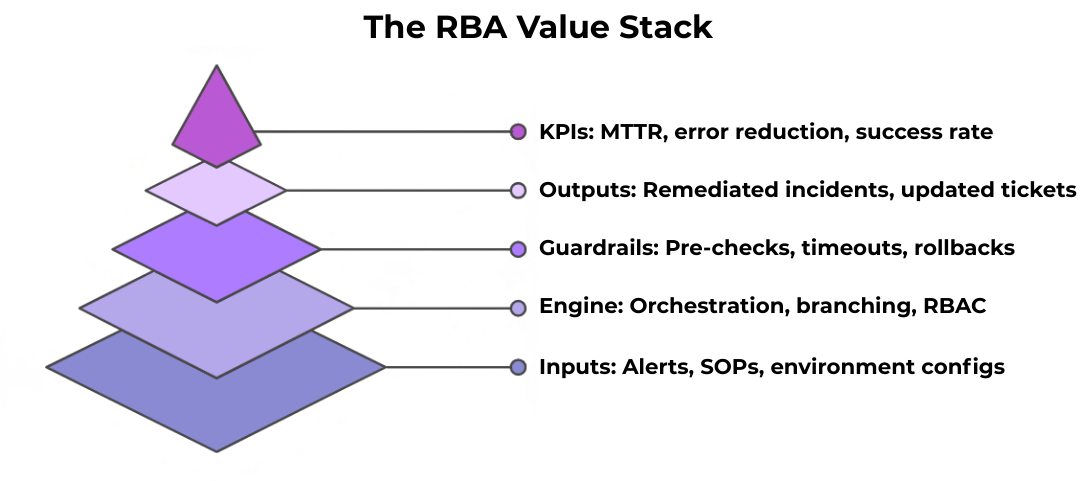
Runbook automation turns inputs (alerts, SOPs) into audited outputs via an orchestrated engine with guardrails—improving KPIs: lower MTTR, fewer errors, higher change success.
How Runbook Automation Fits into Your Toolchain
RBA sits at the crossroads of monitoring, chat, CI/CD, ITSM, and cloud. Alerts can trigger runbooks directly; ChatOps enables on-call engineers to pass parameters and approve actions without leaving Slack/Teams; ITSM tickets open automatically and attach run artifacts; CI/CD pipelines call runbooks for pre-deploy checks or post-deploy rollbacks; and cloud integrations let runbooks modify infrastructure through least-privilege APIs.
Treat RBA as a fabric rather than an island. The more it participates in your existing flows, the higher your adoption and the faster your outcomes improve.
Common Pitfalls
Organizations sometimes try to automate everything at once and ship fragile workflows. A better approach is incremental: start with small, high-leverage tasks and expand. Another pitfall is credential sprawl-secrets copied into scripts and repos-when a central store with per-step scoping is safer and easier. Finally, silent failures are pernicious. If a runbook fails and no one sees it, you haven’t reduced risk-you’ve hidden it. Build strong error surfaces, comprehensive logging, and alerting on run failures from day one.
Where GenAI Helps
Generative AI is a helpful assistant, not an autonomous operator. It can draft runbook steps from incident timelines, suggest pre-check patterns, or summarize runs into human-readable updates. Keep AI-assisted actions behind approvals, never grant it access to mint or exfiltrate secrets, and require human oversight for production-impacting changes. Used this way, AI reduces toil while preserving accountability.
Tool Evaluation: Questions to Ask in Every Demo
- – Does it support event-, schedule-, and human-initiated runs with branching and parallelism?
- – Can we enforce per-step credentials with centralized secrets, redaction, and environment scoping?
- – Do we get live run views, per-step logs, artifact capture, and straightforward export to SIEM/APM?
- – Is there a no-code builder for operators and a CLI/SDK for engineers with versioning and promotion gates?
- – How are approvals, change control, and audit trails implemented, and can they map to our compliance requirements?
Conclusion
Runbook automation turns operational excellence into a repeatable system. By encoding your best procedures as executable, observable workflows-with approvals and guardrails-you accelerate recovery, reduce change risk, and give engineers back the hours they’ve been paying in toil. Start with a handful of high-frequency tasks, instrument outcomes, and expand methodically. Within a few sprints you’ll see the numbers-and the culture-move in the right direction.
Call to action: Ready to make incidents boring and engineering time precious again? Pilot three automated runbooks this month-one in SRE, one in IT, and one in Security-track your metrics, and iterate. If you need help designing safe, auditable workflows that fit your stack, our team is here to partner with you.
FAQ
How is runbook automation different from SOAR or job schedulers?
SOAR is security-specific incident orchestration, while schedulers optimize time-based or batch workloads. RBA spans DevOps, IT, and Security with event- or human-triggered actions, risk-scaled approvals, and verification steps designed for reliability.
Do we still need engineers if the tool is low-code?
Yes. Low-code accelerates assembly, but engineers ensure idempotency, safe defaults, and integration quality. The best programs pair a visual builder for operators with a CLI/SDK for tests, linting, and promotion.
Could automation increase outage risk?
Without guardrails yes. With pre-checks, approvals, timeouts, retries, and rollbacks, RBA reduces risk by making failure modes explicit and recoverable.
How fast will we see results?
Time to First Action typically drops immediately when chat- or alert-triggered runbooks go live. MTTR improvement follows as coverage expands and verification hardens.
How do we pick the first runbooks to automate?
Choose high-frequency, low-risk tasks with clear success criteria: service restarts with validation, cache flushes, user unlocks, and key rotations. Validate in staging, shadow-run during incidents, then promote with approvals.
Like what you see? Share with a friend.
Itay Guttman
Co-founder & CEO at Engini.io
With 11 years in SaaS, I've built MillionVerifier and SAAS First. Passionate about SaaS, data, and AI. Let's connect if you share the same drive for success!
Share with your community


.png)
Comments