
Local LLMs for SaaS Companies: Unlock Speed, Privacy, and Full Control
Large Language Models (LLMs) are reshaping the SaaS landscape by powering features like chatbots, smart search, summarization, and recommendation engines. Traditionally, most AI functionality in SaaS products has relied on cloud APIs but this comes with significant downsides. Latency, unpredictable costs, and data privacy concerns are prompting many teams to seek alternatives. A local LLM for SaaS offers a transformative solution. These language models run entirely within your own infrastructure, eliminating reliance on third-party APIs. They allow companies to boost performance, control costs, and maintain full ownership of sensitive data.
What Is a Local LLM?
A local LLM is a language model deployed entirely within infrastructure you control-on-premise, in a private cloud, or on edge devices. Unlike cloud APIs, which process data off-site, local LLMs keep inference local, meaning no data ever leaves your environment.
This distinction is critical for SaaS companies that manage sensitive customer information or fall under strict compliance requirements. Running models locally reduces latency, improves security posture, and enables advanced customization. For instance, real-time response times drop dramatically-often under 50ms-and fine-tuning becomes far more flexible.
Open-source models like Meta’s LLaMA 2, Mistral 7B, Gemma, Falcon, and Phi-2 have opened the door to local deployment. These models can be run efficiently using frameworks like llama.cpp, vLLM, and text-generation-webui, especially when quantized using formats like GGUF.
Why SaaS Companies Are Adopting Local LLMs
Local models offer more than just cost savings. They represent a fundamental shift in how SaaS platforms approach AI infrastructure.
For many companies, privacy is the top concern. Internal documents, customer conversations, and behavioral data can’t always be safely transmitted to third-party APIs-especially when governed by laws like GDPR, HIPAA, or SOC 2. Local models allow full data control, simplifying compliance and auditability.
Performance is another key driver. Cloud APIs introduce unpredictable latency. In contrast, local inference can be near-instant, enabling smoother UX for real-time applications like IDE completions or support bots. Over time, the cost model also becomes more favorable: instead of per-token billing, teams invest in fixed infrastructure with predictable scaling.
Customization is the final edge. With local LLMs, developers can fine-tune behavior using internal tickets, product documentation, or customer feedback-creating outputs that align with brand voice and user expectations.
Use Cases in SaaS Products
Local LLMs are already delivering value across a wide range of SaaS tools.
In customer support, internal chatbots trained on private ticket data can answer user queries without ever transmitting content externally. Document summarization engines can process PDFs and email threads directly within secure environments. Smart search engines benefit from personalization without syncing to third-party data centers.
Several companies are leading the charge. A fintech SaaS uses Mistral 7B locally for contract analysis. An HR platform uses llama.cpp to parse CVs on-device. A dev tool startup runs GGUF quantized models inside a native IDE plugin, offering offline code assistance.

Feature-by-feature comparison of cloud-based LLMs versus local deployment for SaaS applications.
How to Deploy a Local LLM
While local inference may sound complex, modern tooling makes it accessible-even to small SaaS teams. Here’s a simplified outline:
- Choose a model that fits your needs. For multilingual apps, Mistral or Falcon are ideal. For hardware-limited environments, GGUF-quantized models offer CPU compatibility.
- Provision infrastructure, either on-premise or using a cloud VM with a suitable GPU (e.g., RTX 4090 or A100).
- Deploy using an inference engine such as llama.cpp, vLLM, or text-generation-webui, and containerize it using Docker for portability.
- Expose the model via an internal API (REST or gRPC), integrating with your app backend.
- Monitor and optimize with performance logging, model batching, quantization, and regular updates.
Tools like LangChain, BentoML, and Hugging Face Transformers streamline many of these steps.
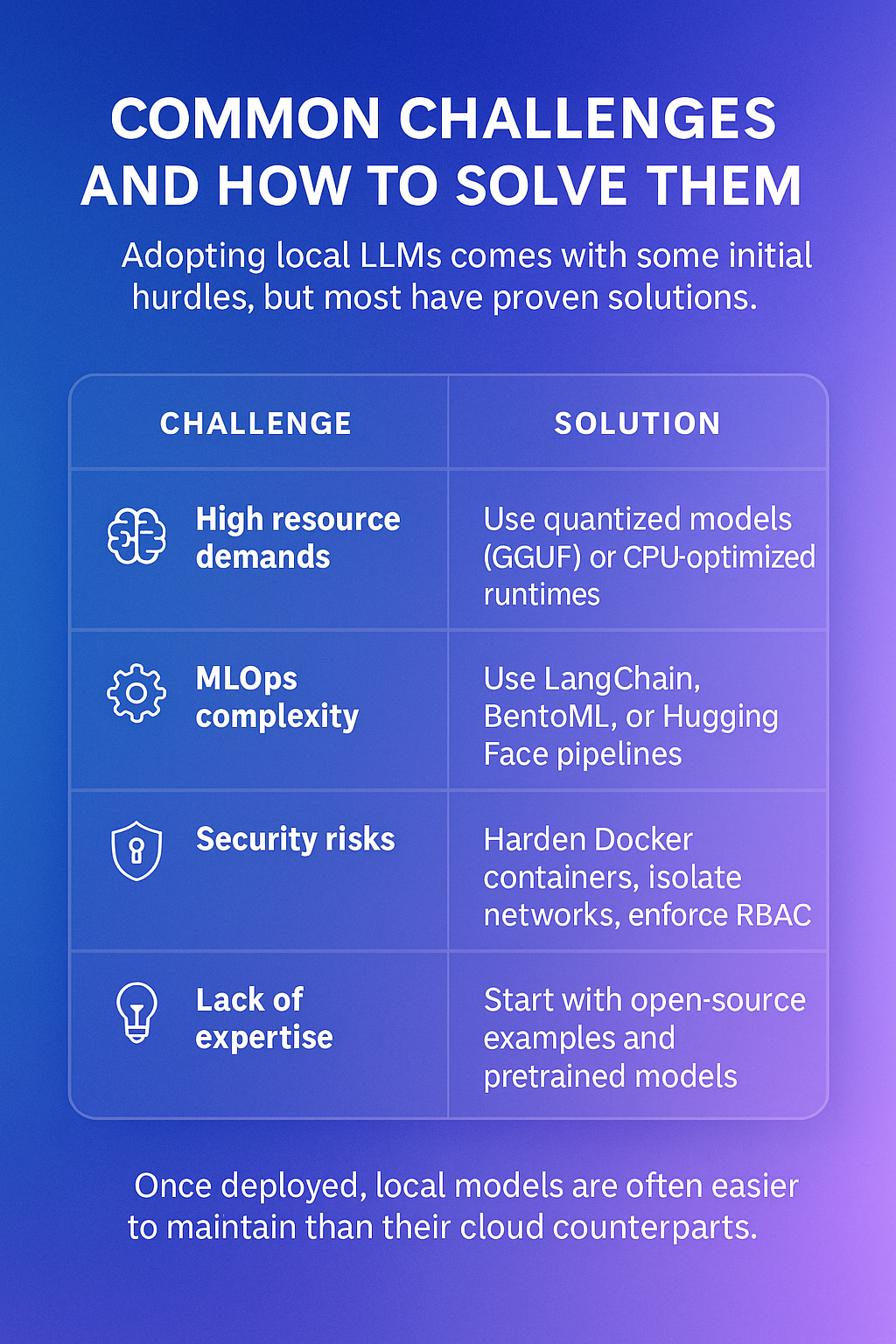
Common obstacles SaaS teams face when adopting local LLMs and the proven ways to overcome them.
Final Thoughts: Take Control of Your AI Stack
SaaS companies need to deliver fast, intelligent, and trustworthy AI experiences-without compromising on privacy or cost. Local LLMs offer that balance. They enable real-time performance, full customization, and total data control at scale.
If you’re exploring local inference, start small. Pick a high-impact use case-such as document summarization or support automation-and prototype using a quantized open-source model. With the right tools, even small teams can deploy powerful local models in days, not months.
FAQ
Answers to common questions about running large language models locally for SaaS products.
What’s the difference between a local LLM and a private API deployment?
Are local LLMs secure for customer data?
How expensive is it to run a local LLM?
Can SaaS companies fine-tune local LLMs with their own data?
Do local LLMs work offline?
Like what you see? Share with a friend.
Itay Guttman
Co-founder & CEO at Engini.io
With 11 years in SaaS, I've built MillionVerifier and SAAS First. Passionate about SaaS, data, and AI. Let's connect if you share the same drive for success!
Share with your community




.png)
Comments